
用影像重建 3D 数位几何架构是电脑视觉一个非常核心的问题。这种技术在许多领域都有广泛应用,例如电影、游戏的内容生成、虚拟实境和扩增实境、3D 打印等。柏克莱人工智能研究中心的 Christian Häne 等人近日发表一篇论文《Hierarchical Surface Prediction for 3D Object Reconstruction》,讨论如何从单张色彩影像重建高品质的 3D 几何架构,就像以下这张图所显示。
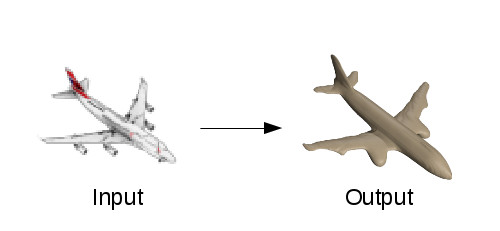
对人类来说,即使只看到一张影像,我们也能毫不费力地理解物体和场域的形状。请注意,眼睛的双目效果允许我们感知深度,我们不需要了解物体 3D 几何架构,即使我们只看到一张实体的照片,也能对它的形状有很好的感知。不仅如此,我们还能理解物体看不见的部分(例如背面),这对拿取物体的动作来说非常重要。于是问题来了,人类是如何从单张影像推理出物体的几何架构?在人工智能方面,我们怎样才能教会机器掌握这能力?
一、形状空间
任意汇入影像来重建 3D 几何架构,基本原理就是:物体形状不是任意,因此有些形状是可能的,有些是不可能的。一般来说,物体的表面往往是光滑的,尤其是人造物体,常常是由几个分段的平面构成。至于预测物体,我们可以使用同样的规则。例如,飞机通常有机身,两侧各有一主翼,后侧会有垂直稳定翼。人类透过眼睛观察世界,并用手与世界互动,然后获得知识。在电脑视觉,“形状不是任意的”这个事实允许我们透过收集大量范例,将一个对象类或多个对象类的所有可能形状,说明成低度形状空间。
使用 CNN 预测体素(Voxel Prediction)
最近 Choy、Girdhar 等人各自发表了关于 3D 重建的论文,在他们的工作中,“汇出”一个 3D 体积空间,这 3D 体积又细分成体积元素(称为体素,voxel),每个体素会有一个规格(被占据或自由空间),而物体形状的预测则表示为由体素组成的 3D 占据体积。在他们的模型中“汇入”一个通常用来说明物体的单色影像,然后他们用卷积神经网络(CNN)的上卷积解码器架构来预测占据体积。该网络线端对端进行训练,并且由已知的 ground truth 占据体积(透过合成 CAD 模型资料集获得)进行监督学习。透过这种 3D 表示(体素)以及 CNN,这种模型就可以学习,且能适应各种对象。
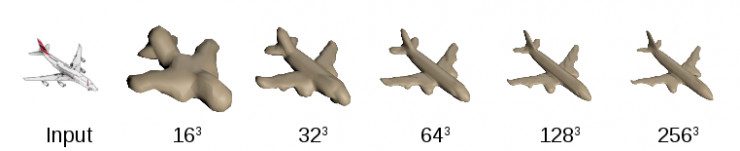
二、层进表面预测
上述方法(使用 CNN 预测占据体积)有一个很大的缺点,由于汇出空间是三度,于是相对增加的分辨率就会以立方增长。这个问题使这种方法难以预测高品质的几何形状,且限于比较粗糙的分辨率体素网格,例如上面 32^3 的结果。Christian Häne 等人的工作中,他们认为这是一个不必要的限制,因为表面只是二度。于是他们透过层进的方式利用表面的二度性质来预测精细分辨率体素,此时只需要高分辨率预测表面即可。其基本思想和八叉树表示的思想关系很近,八叉树表示通常用于多视图立体声和深度图融合等领域,来表示高分辨率的几何架构。
方法
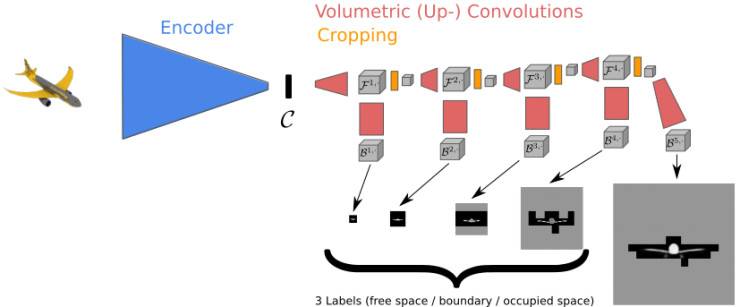
在这个 3D 预测模型(称为层进表面预测[Hierarchical Surface Prediction,HSP])中,首先我们汇入一张单色影像,用卷积编码器将其编码为低度表示。然后,将该低度表示解码成 3D 使用体积。主要思想是透过预测低分辨率体素开始解码。关键之处在于,不同于标准的方法将体素分为占据/自由空间,HSP 会将体素分为 3 类:自由空间、占据空间和边线。使用这种方法,“汇出”的分辨率可以很低,只要保证在那些有迹象表明它包含“边线”的部分有较高分辨率即可。透过更新,我们可以层进预测出高分辨率的体素网格。更多模型的细节可参看论文。
实验
模型的实验主要利用合成的 ShapeNet 资料集训练。作者将结果与两个基线模型──硬低分辨率模型(low resolution hard,LR hard)和软低分辨率模型(low resolution soft,LR soft)对比。这两个基线模型都是以 32^3 粗分辨率预测,只是训练资料的生成方式不同。LR hard 对体素使用双分法进行规格,即如果在相应的高分辨率体素中至少一个被使用,则所有体素记号为被使用。LR soft 则使用分数法进行规格,每个体素将反映出在相关高分辨率体素占有的百分比。HSP 方法以 256^3 分辨率预测。下面的结果显示,HSP 方法与基线方法相比,在表面品质和高分辨率预测的完整性方面表现更好。

- High Quality 3D Object Reconstruction from a Single Color Image
相关论文:
- Hierarchical Surface Prediction for 3D Object Reconstruction(Christian Häne 等)
- 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction(Choy 等)
- Learning a Predictable and Generative Vector Representation for Objects(Girdhar 等)
- ShapeNet: An Information-Rich 3D Model Repository(关于 ShapeNet 资料集的论文)
(本文由 雷锋网 授权转载;首图来源:pixabay)







