
在生物和医学领域,研究员常运用显微镜来观察肉眼无法获得的细胞细节讯息。虽然运用透射光显微镜(对生物样本单侧照射生成像),观察起来相对简单且活体培养样本具良好耐受性,但生成的图像难以正确评估。萤光显微技术中会用萤光分子染色需要观察的目标(比如细胞核),能简化分析过程,但仍需要复杂的样品制备。随着包括图像质量自动评估算法和协助病理医师诊断癌组织等机器学习技术,在显微镜领域的应用越来越广泛,Google 因此考虑是否可结合透射光显微镜和萤光显微镜这两种显微镜技术开发一种深度学习系统,进而最大限度降低两者的不足之处。
4 月 12 日,Google 发表了结合透射光显微镜和萤光显微镜这两种显微镜技术,并利用深度学习标记显微镜细胞图像为分色萤光的研究论文,研究内容编译如下。
4 月 12 日出版的《Cell》 杂志刊登了 Google 的论文《In Silico Labeling: Predicting Fluorescent Labels in Unlabeled Images》,展示了深层神经网络能通过透视光图像来预测萤光图像,无需修改细胞就可以生成有标签、有用的图像,这将使长期追踪分析未修改的细胞、在细胞治疗时最大程度减少侵入性细胞检查、同时运用大量标签分析成为可能。对于这项研究,Google 开源了网络设计、完整的训练数据和测试数据、经过训练后的模型检查点及范例代码。
研究背景
透射光显微镜技术虽然易用,但也会生成难以分辨的图像。例如,下图就是一张相衬显微镜得到的图像,其中像素颜色深度表示光线穿过样本时相位变化的程度。
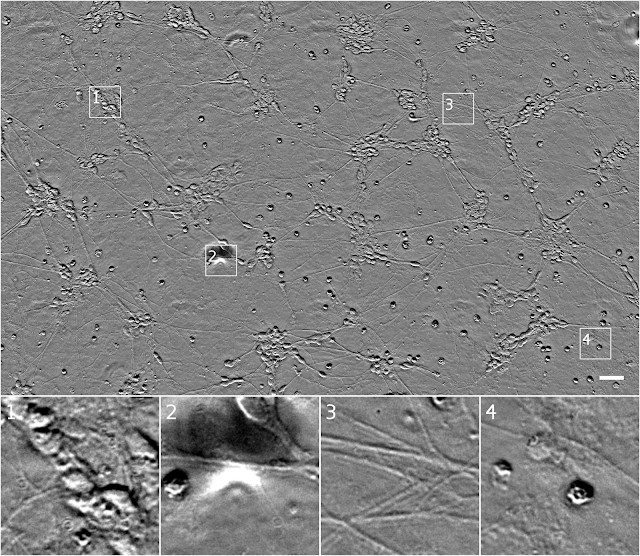
▲ 上图均为自多功能干细胞的人体运动神经元培养物在透射光显微镜下(运用相位对比法)观察到的图像。图 1:可能为神经元细胞。图 2:观察图像的缺陷致掩盖了下方的细胞。图 3:神经突图像。图 4:可能为死亡细胞。比例尺:40μm。上述图像及数字均来自斯通研究所的 Finkbeiner 实验室。
在上图中,很难分辨出图 1 的细胞群单元数量,或者图 4 细胞的位置和状态(提示:上部中间位置有一个几乎不可见的扁平细胞)。同时也很难始终让精细结构保持在对焦范围内,比如图 3 的神经树突。
我们可以透过采集不同 z 高度的图像来获取透射光显微镜下更多讯息:一组关于(x,y)位置的图像,控制其中的 z(距离摄影机的距离)系统地变化。这导致细胞的不同部分对焦或脱焦,进而提供样本细胞的 3D 结构讯息。不幸的是,通常只有有经验的分析人员才能看懂这不同高度的图像,如何分析这种不同高度图像,也是自动化分析过程的巨大挑战。下面即为一个 z 堆栈范例图。
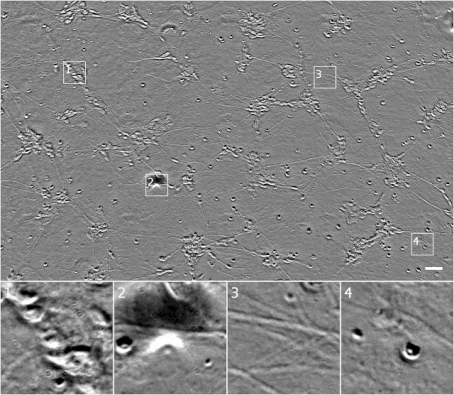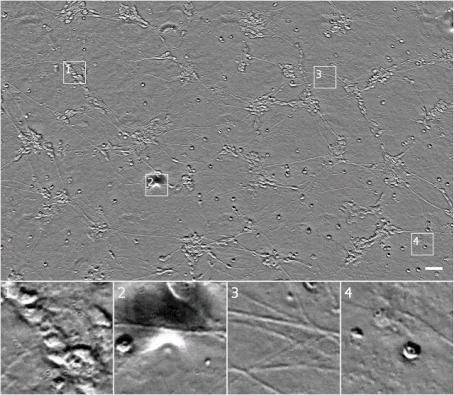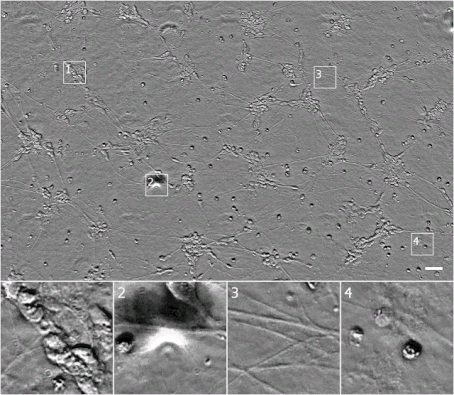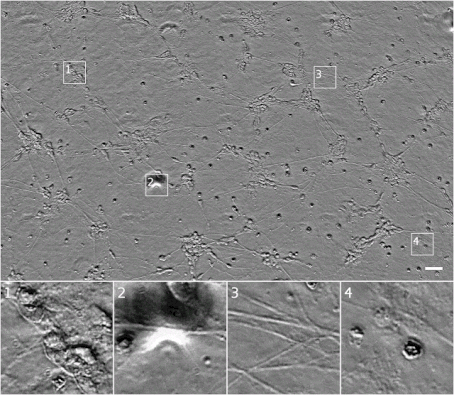
▲ 相同细胞的相位对比 z 堆栈。需要注意,当焦点转移时细胞外观将发生如何变化。我们现在可以观察到图 1 右下角的模糊形状是一个单一椭圆形单元,图 4 最右细胞要比最上面的细胞高,这可能表明它已经历了细胞程序性死亡。
相比上图的透视光图像,下方用萤光显微镜观察到的图像就容易分析多了,因为研究人员将想观察的内容用萤光精心标记。例如,大多数人类细胞只有一个细胞核,因此可以标记细胞核(如下图蓝色标记),这也使利用简单工具统计图像中的细胞数量成为可能。
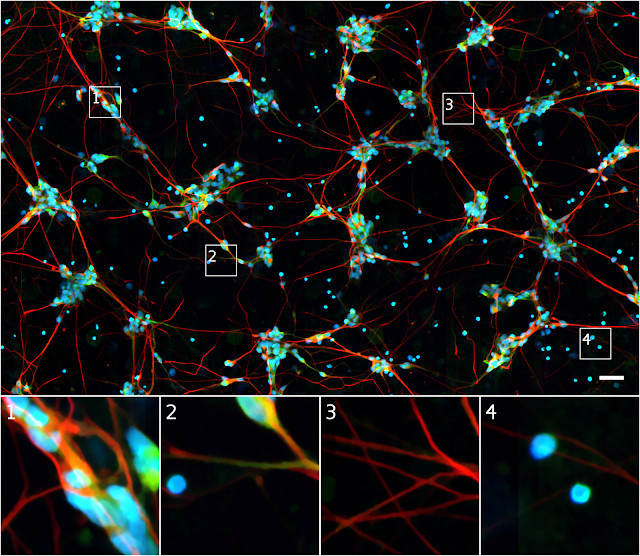
▲ 同一细胞在萤光显微镜下的图像。蓝色萤光标记 DNA 以突出细胞核。绿色萤光标记仅存在树突中的一种神经子结构蛋白质。红色萤光标记仅存在轴突中另一种神经子结构的蛋白质。分色萤光标记帮助研究人员更容易了解样本。例如,通过图 1 绿色和红光萤光标记,可确认这是一个神经群集。图 3 的红色萤光标签代表轴突而非树突。图 4 左上角蓝色的萤光标记揭示之前透过光透视显微镜难以观察到的细胞核,而左侧的细胞缺乏蓝色萤光标记,因此为无 DNA 的细胞碎片。
同时,萤光显微镜也有明显硬伤。首先,样本的制备和萤光标记本身就带来复杂性和可变性。其次,当样本有许多且不同的萤光标记时,光谱的重叠会导致难以分辨哪种颜色对应哪种标记。所以通常会限制研究人员在同一样本最多使用三或四个标记,以免混淆。第三,萤光标记可能对样本细胞产生毒性,有时还会致其死亡,这个缺陷也使萤光标记在需要长时间观察细胞的纵向研究中难以实施。
与深度学习同行,看到更多可能
Google 这篇论文,作者展示了深度神经网络可根据透射光 z 堆栈来预测其分色萤光图像。为此,我们创建了投射光 z 堆栈与分色萤光图像匹配的数据集,并训练神经网络根据投射光 z 堆栈来预测其分色萤光图像。下面就是训练过程的图示介绍。
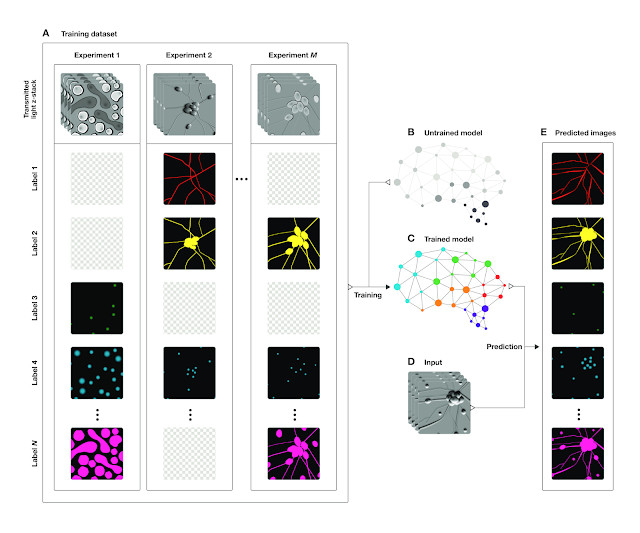
▲ 这是训练系统的概述:(A)为训练实例的数据集:同一样本画面里 z 堆栈的透射光图像和萤光标记图像的像素匹配集。使用不同颜色萤光进行标记产生的萤光标记图像,随着不同训练实例的切换而改变颜色变化;其中类似棋盘图像因未给定实例而无萤光标记。未经训练的深度网络(B)预测数据 A,训练之后再预测数据 A 就变成了(C)。数据 A 的投射光 z 堆栈图像(D)。(E):利用训练后的深度神经,根据 A 数据的每个新图像像素讯息(D)来预测 A 数据的萤光标记(C)。
研究过程中,Google 由 Inception 的模组化设计获得灵感,开发了一种由三种基本构建块组成的新型神经网络:第一种,保持比例的模组配置,不会改变特征的空间尺度大小;第二种,缩小比例的模组配置,会把空间比例缩放为 2 倍;第三种,放大比例,把空间比例缩放为一半。这使网络架构设计难题分成两个更简单的问题:构建块(宏架构)的安排部分和构建块本身(微架构)的设计部分。Google 使用本文前面讨论的设计原则解决了第一个问题,第二个问题则利用 Google Hypertune 的自动搜索来达成。
为了保证本研究方法合理,Google 使用了 Alphabet 实验室以及两个外部合作伙伴的数据验证模型:Gladstone 研究所 Steve Finkbeiner 实验室和哈佛 Rubin 实验室。这些数据涵盖三种透射光成像模式(明场,相差和微分干涉对比)和三种培养类型(来自诱导多功能干细胞的人体运动神经元,大鼠皮质培养物和人体乳腺癌细胞)。Google 发现,该方法可准确预测包括细胞核,细胞类型(如神经)和细胞状态(如细胞死亡)在内的几种萤光标记。下图显示该模型输入神经元范例的透射光后,得出的分色萤光标记预测结果。
输入神经元范例的透射光:输出萤光标记预测结果
▲ 范例图显示了投射光和萤光标记成像的相同细胞图像,以及 Google 模型对其预测生成萤光标记。尽管输入的图像存在伪像(记号 2 图像),但是模型依旧预测生成了正确的萤光标记。(记号 3 图像)根据细胞之间的最近距离推测出这些为轴突。(记号 4 图像)显示了顶部难以发现的细胞,并将左侧的物体正确地标记识别为无 DNA 细胞碎片。
自己亲自动手试试吧!
Google 已开源了该模型、完整数据集、训练、推理代码以及一个范例。Google 还声称,只需借助最少的额外数据训练就能生成新标注/标签:在相关论文和范例代码,Google 展示了根据单张图像就可学会生成萤光标记。这要归功于迁移学习:如果模型已可掌握类似任务,那么就能更快学习新任务,并使用更少的训练数据。
Google 希望在不修改细胞的情况下生成标记、有用的图像,这也将为生物学和医学研究开创全新的实验类型。如果你希望在自己的研究尝试这项技术,可以阅读《In Silico Labeling: Predicting Fluorescent Labels in Unlabeled Images》论文,或前往 github 页面查看模型代码!
- Seeing More with In Silico Labeling of Microscopy Images
(本文由 雷锋网 授权转载;首图来源:科技新报)







